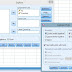
R studio merupakan program open source yang digunakan untuk melengkapi R Statistics. Dengan adanya
R Studio, tampilan akan lebih menarik dan lebih memudahkan karena R Studio
mampu memberikan instruksi-instruksi terkait penulisan script atau kesalahan penulisan script. Untuk menginstal R Studio sudah dijelaskan di tulisan sebelumnya.
Tulisan ini akan memberikan pengenalan tampilan dalam R Studio berserta
masing-masing fungsinya serta bagaimana menginstall packages ke dalam R Studio.
Tampilan R Studio
Secara umum, tampilan R Studio akan terbagi menjadi empat
kotak, yakni: 1) Script editor, 2) Console editor, 3) Workspace dan History, 4)
Files, Plot, Packages, dan help. Jika kita pertama kali menginstall R Studio
biasanya kotak Script editor belum muncul. Untuk memunculkan script editor kita
klik file – new file – R Script.
Script editor
Meruakan tempat untuk menuliskan
kode/instruksi/komentar R agar dapat tersimpan dalam file. Semua script yang dituliskan di kotak script editor ini akan tetap
tersimpan meskipun kita menutup tanpa menyimpan
Console Editor
Merupakan tempat untuk menjalankan perintah (Run) dari
instruksi atau kode R yang ditulis. Hampir sama
seperti di script editor, namun tidak akan tersimpan secara otomatis. Selain
itu hasil output semua analisis juga akan muncul di console editor ini
Workspace dan Histroy
Tab workspace menampilkan
seluruh obyek yang aktif, seperti data kita atau value yang kita
tentukan.
Tab history menampilkan
urutan perintah (list of commands) yang telah
dijalankan
Files, Plot, Packages, Help
Tab files menampilkan
seluruh file dan folder.
Tab plots akan
menampilkan seluruh grafik.
Tab packages akan
menampilkan listing packages atau add-ons yang
diperlukan agar program berjalan dengan baik
Tab help menampilkan
penjelasan yang lengkap dan komprehensif apabila ada instruksi (code)
yang tidak jelas, dilengkapi contohnya.
Setting Working
Directory
Tahap awal yang penting untuk dilakukan sebelum kita
memulai menggunakan R Studia adalah menentukan lokasi di folder mana kita akan
bekerja, mendapatkan, dan menyimpanfile kita. Cara menentukan working directory kita adalah dengan klik session – set working directory – choose directory.
Kemudian pilih folder mana yang akan kita gunakan. Misalkan kita menyimpan
file di "C:/Users/Hanif/Google Drive/BLOGSPOT", maka pada console
editor akan muncul tulisan seperti ini: setwd("C:/Users/Hanif/Google
Drive/BLOGSPOT"). Kita juga dapat langsung mengetikkan script
tersebut di console, maka hasilnya akan sama saja.
Untuk melihat dile apa saja yang ada dalam working
directory kita, kita bisa mengetikkan perintah dir() lalu tekan enter. Maka akan
muncul seperti ini
Itu adalah isi dari folder yang kita tentukan tadi.
Menginstall
Packages
Packages merupakan fitur-fitur yang ada dalam R Studio
yang digunakan untuk melakukan analisis atau menampilkan sesuatu. Masing-masing
packages memiliki fungsinya masing-masing. Packages ini dikembangkan oleh para
ahli dari seluruh duni dan masih terus berkembang hingga saat ini. Terhitung
jumlah packages yang ada saat ini kurang lebih 7000 packages.
Untuk menginstall packages,
ketik di console editor install.packages("nama packages"), lalu tekan enter. Maka R Studio secara otomatis
akan mendownload dan menginstall packages tersebut dari website CRAN. Untuk menginstall
packages tersebut kita wajib terhubung dengan internet. Setelah packages
selesai terinstall kita dapat menjalankannya dalam R dengan mengetik script library(nama packages) pada console editor, lalu tekan enter.
Sebagai contoh, apabila kita ingin R Studio kita mampu
membaca file dengan format SPSS, maka kita membutuhkan library foreign. Oleh karena itu, sebelum kita
mengaktifkannya kita perlu menginstal dengan mengetik script install.packages("foreign"). Setelah semua selesai
terinstall, maka kita bisa mengaktifkannya dengan mengetik script library(foreign).
Selain packages foreign yang berfungsi membaca file SPSS,
masih banyak packages lain seperti untuk membaca file excel, menampilkan grafik,
analisis item, dll. Beberapa packages lain yang wajib dimiliki sebagai dasar
penggunaan R Studio dapat dilihat disini. Beberapa packages lainnya dapat dicari dengan mudah di google.

Tulisan ini sebenarnya merupakan tugas mata kuliah Psikologi Positif, yaitu untuk mereview salah satu chapter dalam buku Psikologi Pertumbuhan karya Duane Schultz (1991). Berhubung tugas ini sudah dikumpulkan dan nilai sudah keluar, dan sayang sekali kalau hanya dosen pengampu mata kuliah saja yang membacanya, maka saya copykan tulisan di sini saja, siapa tahu bisa lebih bermanfaat.